The field of document understanding has seen a surge of multimodal models, but few manage to balance accuracy, multilingual versatility, and computational efficiency the way PaddleOCR-VL-0.9B does. This state-of-the-art (SOTA) vision-language model from PaddlePaddle redefines document parsing with its innovative fusion of a NaViT-style dynamic-resolution visual encoder and the ERNIE-4.5-0.3B language model, enabling pixel-level precision and intelligent text comprehension in a single framework. Whether it’s parsing dense tables, intricate mathematical formulas, or multilingual text layouts, PaddleOCR-VL-1B delivers exceptional element-level accuracy while maintaining lightweight resource usage. The model supports 109 languages, from English, Chinese, and Arabic to Hindi and Thai, making it a truly global solution for enterprises and researchers alike. Its optimized architecture not only outperforms traditional OCR pipelines but also achieves SOTA results on public and in-house benchmarks, bringing large-scale document understanding within reach of standard hardware setups.
In this guide, we’ll show you how to install and run PaddleOCR-VL-0.9B locally, so you can harness its cutting-edge multilingual and multimodal capabilities directly on your machine or inside a GPU accelerated environment.
Prerequisites
The minimum system requirements for running this model are:
- GPU: 1x RTX4090 or 1x RTX A6000 (depending on the use case scale)
- Storage: 20 GB (preferable)
- VRAM: at least 16 GB
- Anaconda installed
Step-by-step process to install and run PaddleOCR-VL
For the purpose of this tutorial, we’ll use a GPU-powered Virtual Machine by NodeShift since it provides high compute Virtual Machines at a very affordable cost on a scale that meets GDPR, SOC2, and ISO27001 requirements. Also, it offers an intuitive and user-friendly interface, making it easier for beginners to get started with Cloud deployments. However, feel free to use any cloud provider of your choice and follow the same steps for the rest of the tutorial.
Step 1: Setting up a NodeShift Account
Visit app.nodeshift.com and create an account by filling in basic details, or continue signing up with your Google/GitHub account.
If you already have an account, login straight to your dashboard.

Step 2: Create a GPU Node
After accessing your account, you should see a dashboard (see image), now:
- Navigate to the menu on the left side.
- Click on the GPU Nodes option.

- Click on Start to start creating your very first GPU node.

These GPU nodes are GPU-powered virtual machines by NodeShift. These nodes are highly customizable and let you control different environmental configurations for GPUs ranging from H100s to A100s, CPUs, RAM, and storage, according to your needs.
Step 3: Selecting configuration for GPU (model, region, storage)
- For this tutorial, we’ll be using 1x RTX A6000 GPU, however, you can choose any GPU as per the prerequisites.
- Similarly, we’ll opt for 200GB storage by sliding the bar. You can also select the region where you want your GPU to reside from the available ones.

Step 4: Choose GPU Configuration and Authentication method
- After selecting your required configuration options, you’ll see the available GPU nodes in your region and according to (or very close to) your configuration. In our case, we’ll choose a 1x RTX A6000 48GB GPU node with 64vCPUs/63GB RAM/200GB SSD.

2. Next, you’ll need to select an authentication method. Two methods are available: Password and SSH Key. We recommend using SSH keys, as they are a more secure option. To create one, head over to our official documentation.

Step 5: Choose an Image
The final step is to choose an image for the VM, which in our case is Nvidia Cuda.

We will switch to the Custom Image tab and select a specific Docker image that meets all runtime and compatibility requirements.
We choose the following image:
nvidia/cuda:12.1.1-devel-ubuntu22.04
This image is essential because it includes:
- Full CUDA toolkit (including
nvcc)
- Proper support for building and running GPU-based applications
- Compatibility with CUDA 12.1.1 required by certain model operations
Launch Mode
We selected:
Interactive shell server
This gives us SSH access and full control over terminal operations — perfect for installing dependencies, running benchmarks, and launching models.

Docker Repository Authentication
We left all fields empty here.
Since the Docker image is publicly available on Docker Hub, no login credentials are required.
Identification
nvidia/cuda:12.1.1-devel-ubuntu22.04

That’s it! You are now ready to deploy the node. Finalize the configuration summary, and if it looks good, click Create to deploy the node.


Step 6: Connect to active Compute Node using SSH
- As soon as you create the node, it will be deployed in a few seconds or a minute. Once deployed, you will see a status Running in green, meaning that our Compute node is ready to use!
- Once your GPU shows this status, navigate to the three dots on the right, click on Connect with SSH, and copy the SSH details that appear.

As you copy the details, follow the below steps to connect to the running GPU VM via SSH:
- Open your terminal, paste the SSH command, and run it.
2. In some cases, your terminal may take your consent before connecting. Enter ‘yes’.
3. A prompt will request a password. Type the SSH password, and you should be connected.
Output:

Next, If you want to check the GPU details, run the following command in the terminal:
!nvidia-smi
Step 7: Set up the project environment with dependencies
- Create a virtual environment with Anaconda.
conda create -n ocr python=3.11 -y && conda activate ocr
Output:
2. Install required packages and dependencies.
python -m pip install paddlepaddle-gpu==3.2.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/
python -m pip install -U "paddleocr[doc-parser]"
python -m pip install https://paddle-whl.bj.bcebos.com/nightly/cu126/safetensors/safetensors-0.6.2.dev0-cp38-abi3-linux_x86_64.whl
Step 8: Download and Run the Model
1. Create a python file named app.py which will contain the inference code.
touch app.py
2. Open the app.py file in the editor of your choice and paste the following code in the file.
nano app.py
from paddleocr import PaddleOCRVL
pipeline = PaddleOCRVL()
output = pipeline.predict("https://paddle-model-ecology.bj.bcebos.com/paddlex/imgs/demo_image/paddleocr_vl_demo.png")
for res in output:
res.print()
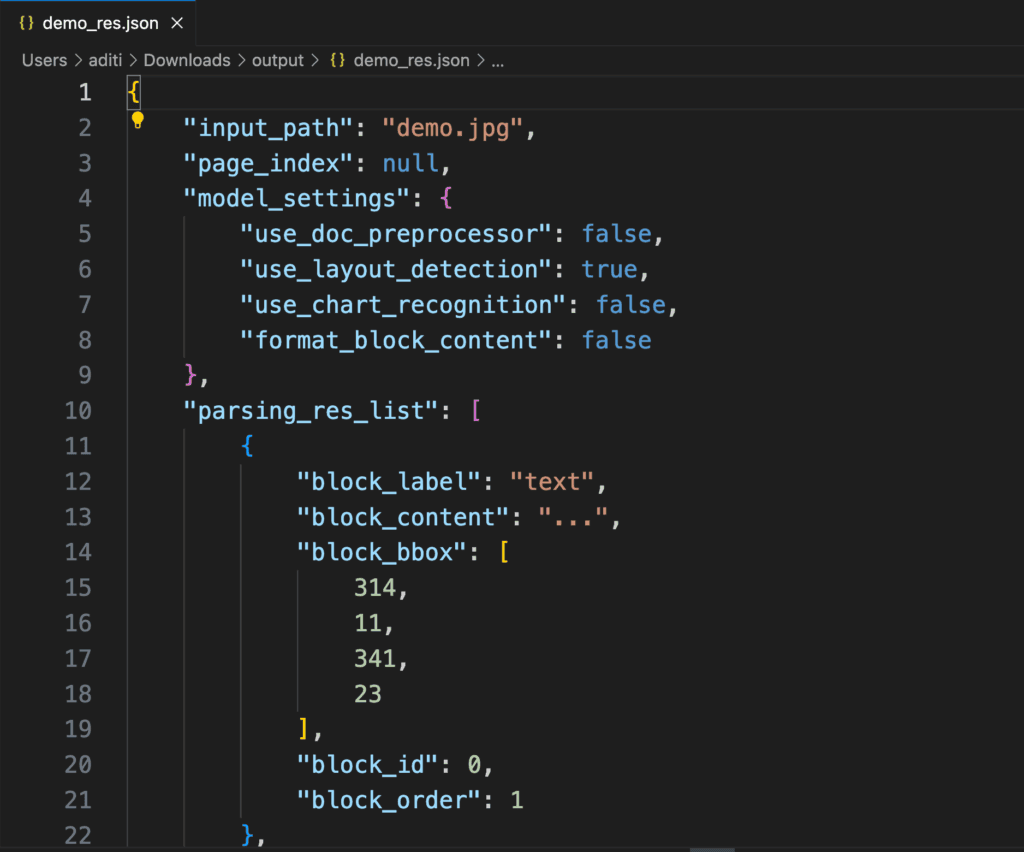
res.save_to_json(save_path="output")
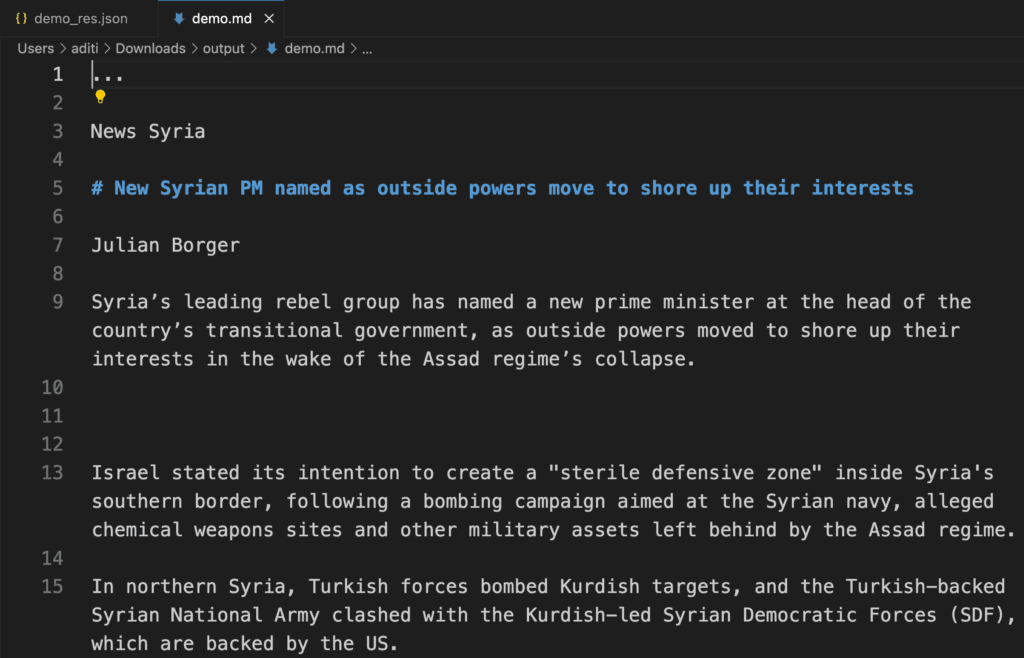
res.save_to_markdown(save_path="output")
Here’s how the code looks in the file:
Make sure you replace the "demo.jpg" with the original path to your test image.
Save the file and close the editor.
3. Run the model for inference.
python app.py
Here’s the image that we pass in for inference: Demo image

You can replace the image with any other image or pdf of your choice by replacing the link in the inference code.
Output:
Annotations
Markdown
Conclusion
PaddleOCR-VL-0.9B stands as a milestone in document intelligence, combining NaViT-style dynamic visual encoding with the ERNIE-4.5-0.3B language model to deliver state-of-the-art accuracy across complex document types and 109 languages, all while remaining remarkably resource-efficient. It bridges the gap between high-performance OCR and real-world usability, empowering users to parse text, tables, formulas, and charts with unmatched precision. NodeShift Cloud further amplifies this power by offering a seamless environment to install, run, and benchmark PaddleOCR-VL locally or in GPU-accelerated setups, removing the friction of manual setup and letting developers focus on experimentation and integration. Together, they make advanced multimodal document understanding both accessible and production-ready.



